
Üniversitedeki son yılımda karşılaştığım en somut problemlerden biri, staj başvuru süreçlerinin hâlâ büyük ölçüde manuel yürütülmesiydi. Yüzlerce CV'nin insan eliyle okunup şirket ihtiyaçlarıyla eşleştirilmesi hem yavaş hem öznel hem de ölçeklenemeyen bir süreç. Bitirme projemde bu problemi, doğal dil işleme ve yapay zekayı bir araya getirerek çözmeye çalıştım: adayların CV'lerini otomatik olarak analiz edip, şirket profilleriyle matematiksel olarak en iyi eşleşen adayları sıralayan uçtan uca bir sistem.
Bu yazıda, projenin mimarisini, kullandığım yöntemleri ve elde ettiğim sonuçları paylaşıyorum.
Problem Tanımı
Manuel staj yerleştirmesi üç temel sorun barındırıyor: öznellik (her değerlendirici farklı kriterlere odaklanıyor), yavaşlık (yüzlerce başvurunun tek tek incelenmesi zaman alıyor) ve ölçeklenemezlik (başvuru sayısı arttıkça sistem çöküyor). Bu projede amacım, yapılandırılmamış CV metinlerini ve şirket gereksinimlerini matematiksel bir eşleştirme çerçevesine dönüştürerek bu üç sorunu birden ortadan kaldırmaktı.
Sistem Mimarisi
Sistem dört ana bileşen üzerine kuruldu: (1) Şirket Verisi Toplama — sektör gereksinimlerini derlemek için, (2) Yapay Zeka Destekli CV Parser — aday yetkinliklerini çıkarmak için, (3) Cosine Similarity Motoru — TF-IDF kullanarak aday-şirket eşleşme skorlarını hesaplamak için, ve (4) API Katmanı — tüm veri akışını yöneten sağlam bir arka uç. Bu dört bileşen birlikte, manuel taramanın kısıtlarını ortadan kaldıran hızlı ve otomatik bir eşleştirme hattı oluşturuyor.
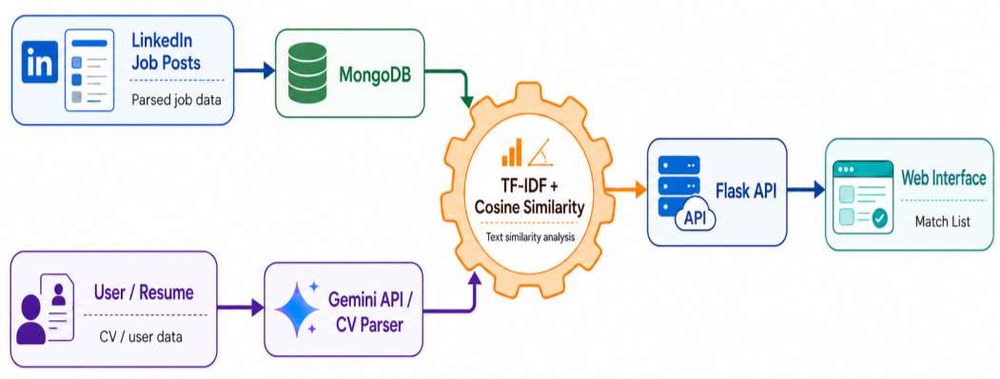
Şekil 1 — CV ve şirket eşleştirme çerçevesinde kullanılan dört ana modülün uçtan uca veri akışı.
Yöntem
1. Şirket Verisi Toplama
Şirket profillerini LinkedIn üzerinden otomatik web kazıma ile topladım: toplanan 513 kayıttan, doğrulama sürecinden geçen 372'si veri setine dahil edilerek MongoDB'de saklandı. Aday CV'leri ise, aynı zamanda parser'ın doğruluğunu test etmek için bir doğrulama ortamı görevi gören özel bir web platformu üzerinden PDF olarak toplandı.
Şekil 2 — 372 şirket kaydını ve veri alanlarını gösteren MongoDB havuz yapısı.

Şekil 3 — Aday CV verisi toplama ve parser doğrulama web platformu arayüzü.
2. CV Parser
Yüklenen PDF özgeçmişler önce PyPDF2 ile ham metne dönüştürülüyor, ardından Google Gemini 2.5 Flash ile yapılandırılmış veriye dönüştürülüyor. Model; isim, iletişim bilgisi, yetenekler, deneyim, eğitim, diller ve yapay zeka tarafından üretilen bir aday özeti (ai_ozet) içeren standart bir JSON nesnesi döndürüyor.
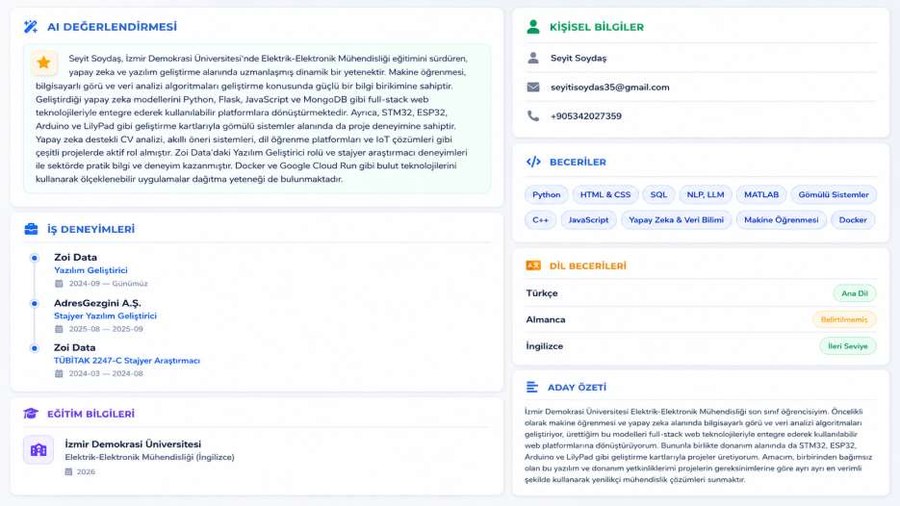
Şekil 4 — Gemini 2.5 Flash tarafından üretilen, çıkarılan yetenek, deneyim, eğitim ve yapay zeka özetini gösteren yapılandırılmış CV parser çıktısı.
3. TF-IDF, Cosine Similarity & Gemini AI Eşleştirme Motoru
Aday ve şirket metinleri, scikit-learn'ün TfidfVectorizer'ı ile bağımsız olarak vektörleştiriliyor (max_features=300, ngram_range=(1,2), sublinear_tf=True). Skorlar, beş ağırlıklı bileşen üzerinden 0-100 arasına min-max normalize ediliyor:
- TF-IDF Cosine Similarity — 55 puan
- Anahtar Kelime Eşleşmesi (TR↔EN) — 15 puan
- Sektör Uyumu — 15 puan
- Deneyim Aktarımı — 10 puan
- Konum Eşleşmesi — 10 puan
Derinlemesine analiz için, en iyi 30 aday Gemini 2.5 Flash'a gönderiliyor ve Teknik Uyum (35p), Sektör Uyumu (25p), Deneyim Aktarımı (20p) ve Kariyer Potansiyeli (20p) kriterlerine göre yeniden değerlendiriliyor. Model, skor ve gerekçe içeren sıralanmış bir JSON dizisi döndürüyor.
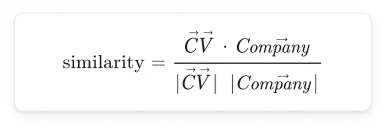
Şekil 5 — Aday-şirket metin vektör hizalamasını hesaplamak için kullanılan cosine similarity formülü.
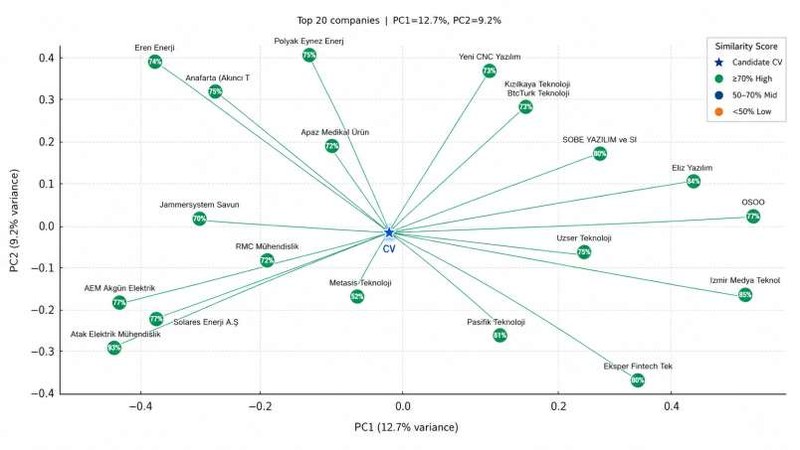
Şekil 6 — TF-IDF vektör uzayı görselleştirmesi: aday CV'si ve en iyi eşleşen 20 şirketin, benzerlik skoruna göre renklendirilmiş PCA 2D projeksiyonu.
Sonuçlar
CV Parser Doğruluğu
Gemini 2.5 Flash tabanlı CV parser, 70 katılımcı değerlendirmesinde %92,1 ortalama doğruluk elde etti. Kişisel Bilgi ve Yetenekler alanları %100 doğruluğa ulaşırken, en düşük skor %75,7 ile Özet alanında görüldü — bu da adayların kendi yazdığı profil metinlerindeki değişkenlikten kaynaklanıyor.
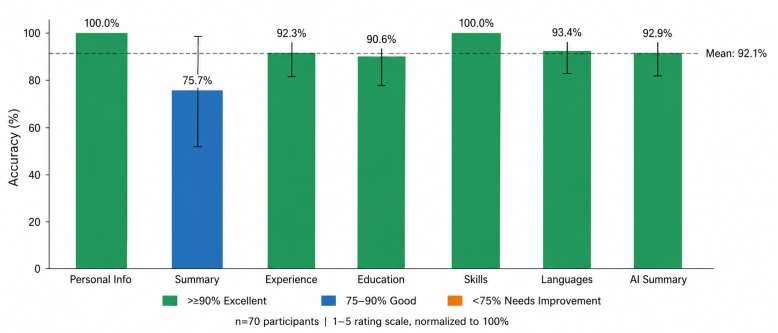
Şekil 7 — 70 katılımcı değerlendirmesine dayalı CV parser alan bazlı doğruluk oranları (1-5 ölçek, %100'e normalize edilmiş, hata çubukları ±1 standart sapma).
Eşleştirme Skoru Dağılımı
Beş bileşenli hibrit skorlama modeli, 372 şirkete uygulandı. En iyi 20 sonuç, her bileşenin (TF-IDF Cosine, Anahtar Kelime Eşleşmesi, Sektör Uyumu, Deneyim Aktarımı, Konum) katkısını gösteren yığılmış bir çubuk grafikle görselleştirildi.
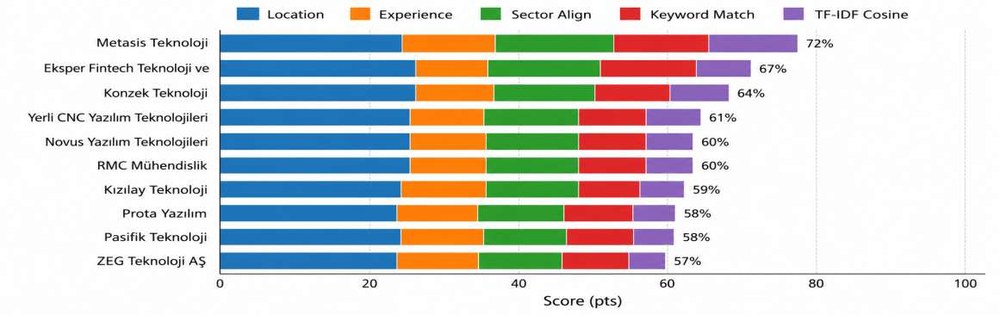
Şekil 8 — En iyi 10 şirket için, her skorlama bileşeninin (TF-IDF Cosine, Anahtar Kelime Eşleşmesi, Sektör Uyumu, Deneyim, Konum) katkısını gösteren eşleştirme skoru dağılımı.
AI vs TF-IDF Karşılaştırması
Gemini AI ve TF-IDF skorları, 15 şirket üzerinden karşılaştırıldığında orta düzey bir korelasyon (Pearson r = 0,46) gösterdi. Yüksek uyum gösteren eşleşmeler (Δ≤%10), her iki modelin de en iyi adaylarda birleştiğini doğrularken, farklılıklar iki modelin birbirini tamamlayan değerlendirme perspektiflerine sahip olduğunu ortaya koydu.
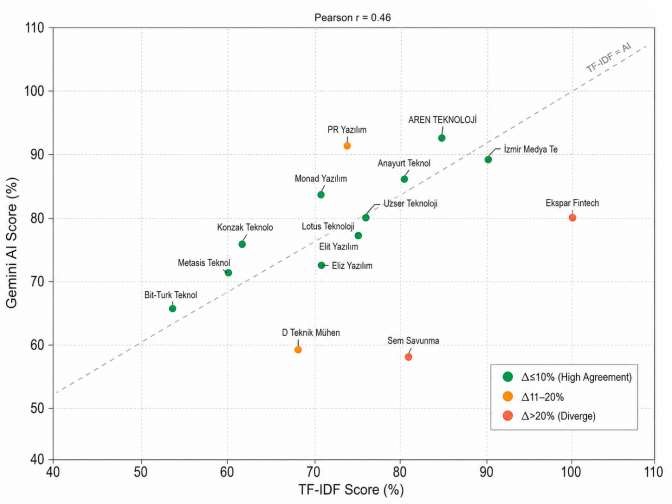
Şekil 9 — 15 şirket üzerinden TF-IDF ve Gemini AI skor karşılaştırması (Pearson r = 0,46). Kesikli çizgiye yakın noktalar, iki model arasında yüksek uyumu gösteriyor.
Çıkarım: TF-IDF tabanlı Cosine Similarity, hızlı ve ölçeklenebilir bir ilk eleme sağlarken; Gemini AI'ın bağlamsal değerlendirmesi, salt anahtar kelime örtüşmesinin kaçırabileceği nitelikleri (kariyer potansiyeli, deneyim aktarımı gibi) yakalayarak sonucu zenginleştiriyor. İki yöntemin birlikte kullanılması, hem hız hem de değerlendirme derinliği açısından avantaj sağlıyor.
Web Platformu
Geliştirdiğim sistem, öğrencilerin CV yükleyip otomatik şirket önerileri alabildiği ve staj başvurularını uçtan uca yönetebildiği canlı bir web platformuna dönüştü.

QR kod, öğrencilerin CV yükleyebildiği, otomatik şirket önerileri alabildiği ve staj başvurularını uçtan uca yönetebildiği yapay zeka destekli Staj Yönetim Sistemi'ne doğrudan erişim sağlıyor.
Sonuç ve Değerlendirme
Bu proje bana, akademik bir fikri (metin benzerliği ve büyük dil modelleri ile eşleştirme) uçtan uca çalışan, gerçek kullanıcı verisiyle test edilmiş bir ürüne dönüştürme deneyimi kazandırdı. %92,1'lik parser doğruluğu ve iki farklı skorlama yönteminin birbirini tamamladığını gösteren sonuçlar, hibrit (klasik NLP + LLM) yaklaşımların tek başına her iki yöntemden de daha güvenilir olabileceğini gösterdi. İleride, eşleştirme modelini gerçek işe alım geri bildirimleriyle ince ayar yaparak (fine-tuning) doğruluğu daha da artırmayı hedefliyorum.
Kaynakça
- Çelik, S., & Oktay, E. (2019). A web-based internship management system design for universities. International Journal of Educational Technology, 6(2), 45–52.
- Lu, Y., El Helou, S., & Gillet, D. (2013). A recommender system for job seeking and recruiting website. Proceedings of WWW, 963–966.
- Salton, G., & Buckley, C. (1988). Term-weighting approaches in automatic text retrieval. Information Processing & Management, 24(5), 513–523.
- Google. (2024). Gemini: A Family of Highly Capable Multimodal Models. Retrieved from deepmind.google/technologies/gemini
- Jiechieu, K. F. F., & Tsopze, N. (2021). Skills prediction based on resume parsing using multilabel classification. Neural Computing and Applications, 33, 5231–5243.
